E-commerce Web Scraping Pipeline
Overview
This project involves the creation of an on-cloud, persistent, web-scraping data pipeline to generate a TB-scale data source for research. In particular, the data spans at least two years of vehicle sale data on large public e-commerce platforms The generated data supports research groups at both the School of Information and School of Environment and Sustainability, at the University of Michigan.
I served as the primary data engineer on this project, performing roles encompassing cloud infrastructure development, web scraping development, and site reliability engineering. I also served as the primary consultant for the research groups, leading stakeholder meetings to discover data requirements, configure data access patterns, and explain performance/cost/reliability trade-offs.
The pipeline went through two key changes:
- Scaling pipeline throughput 100x
- Redesigning pipeline to save costs by more than 2x
Technical Components
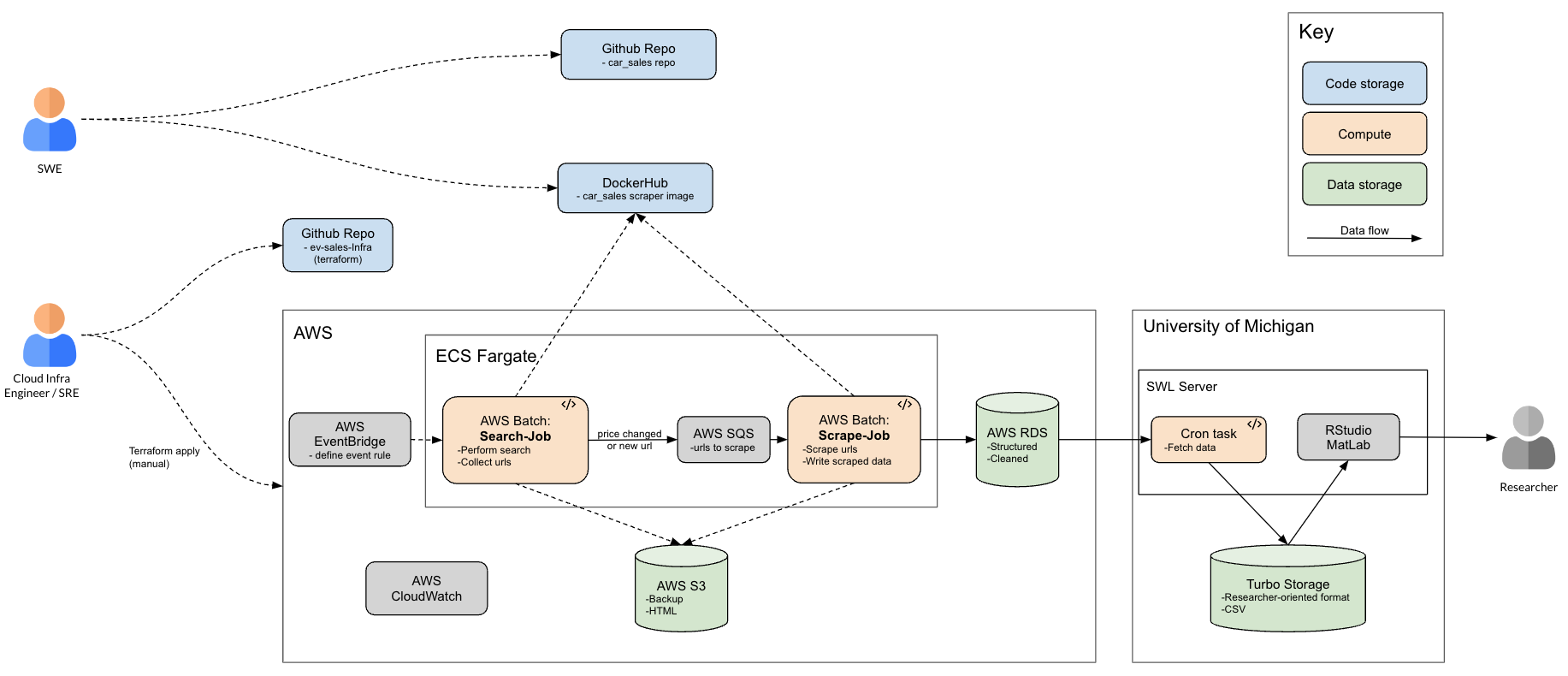
Technologies and Tools
- Web scraping: Selenium, BeautifulSoup
- Data processing: Python, Pandas, json (package)
- CICD and Containerization: Docker, Terraform, Git, Bash
- Cloud technologies: AWS Batch, CloudWatch EventBridge, Lambda, S3, SQS, RDS
Requirements
Data requirements:
- Subjects: Vehicle listings on several e-commerce platforms, across 17 major American cities
- Scraping rate and length: Once a day, every day, for 2+ years.
- Columns (researcher-defined): Essential (VIN#, price, etc.), Important (make, model, etc.), and Nice to Have (seller description, etc.)
- Freshness: Price changes should be captured at a daily granularity; other data should be as fresh as the last time the price changed.
Scale:
- Up to 200k new listings encountered per day, 20k of which are new.
- End user receives about 0.5GB data per day.
Fault tolerance, data backup, and safety:
- Data stores should be protected from outside interference; No need to encrypt data at rest since information is publicly accessible.
- Telemetry should identify scraping and pipeline issues day-of.
- Should be able to reconstruct end-user datasets, backwards in time if necessary, even if key services fail.
Services
Search job (AWS Batch job)- Interact with e-commerce platforms by performing searches for vehicles.
- Submit scrape-job (see below) for listings that need scraping (i.e. they are new or prices have changed)
- Update data stores.
- Load listing and scrape required attributes.
- Save html copy as backup.
- Update data stores.
- Automatically generate researchers' end datasets.
- Automatically report health, status, and behavior of pipeline components.
- Email daily reports to team to quickly identify anomalies and issues.
Highlighted tasks
Scaling pipeline 100x
Before Fall of 2023 the stakeholders were interested in researching only Electric Vehicles. Later, we realized that they also wanted to capture all vehicle data, and not just EV's. Practically, this resulted in a 100x increase in throughput of our pipeline
From a project management standpoint, I took the lead explicating the engineering challenges to both the stakeholders and the engineering team .
From a technical standpoint, I quickly realized that every component of the pipeline would be stressed at the 100x level. A quick summary of changes I implemented:
- I developed telemetry code to determine whether code changes and features worked at scale.
-
I improved and abstracted services to handle 100x usage, in volume and parallel invocation.
- For search-jobs, I implemented recursive web crawling to mimic pagination; I also pre-tested recursion trees to determine strategic start nodes that keep platform GET requests low.
- For data-jobs, I abstracted the number of URLs scraped per job; Through pretesting I increased this number to decrease data-jobs per day, but not too much to trigger platform blockage.
- Similarly, for Lambdas I abstracted the number of S3 files processed per function call, and increased this number to balance between Lambda invoke time and Lambda execution time.
- I spaced out Lambda invokes in time to avoid too many connections to DB.
- For the database, I implemented indices on columns that were frequently filtered on; I also started implementing a retention period to keep the size below capacity.
- I implemented visibility timeouts on SQS messages to avoid duplicate message sends.
Cutting costs by half
After adjusting the pipeline to accommodate a 100x throughput, we quickly realized that the costs of our pipeline would be tremendous, and increase month over month. So, I redesigned the pipeline, including components and services, to decrease costs while maintaining requirements.
My first step after redesigning was to perform a cost/benefit analysis:
- Costs included time to implement and the decrease in data freshness and granularity.
- Benefits included saving at least 50% on compute costs, 10x on storage costs, and a 10x increase in DB data retention period.
- In the end, we confirmed with stakeholders that the costs were absolutely worth the benefits.
From a technical standpoint, I implemented the following changes:
- I again increased the number of URL scraping tasks per data-job, cutting Batch costs in half.
- I redesigned the Database schema to decrease redundancies and sacrifice some granularity, increasing capacity by 10x.
- I added logic for calling data-jobs, calling it only if the price changed or the URL is new, which decreased Batch calls for those jobs by 10x.
- I changed S3 insertion based off the same logic, which made S3 costs increase at a rate 10x less than before.